To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
Text-to-3D generation faces major obstacles due to the lack of large-scale text-annotated 3D datasets. To overcome this, 2D lifting techniques have emerged as a promising approach. These methods leverage pre-trained text-to-image diffusion models and use score distillation sampling (SDS) to refine 3D models from textual inputs. Unlike traditional 3D supervised methods, SDS utilizes the extensive knowledge embedded in pre-trained text-to-image models. This approach bypasses the constraints of dataset scarcity and enhances the ability to generate innovative and previously unseen content.
However, commonly used 2D lifting techniques often suffer from geometric inconsistencies, such as the multi-faced Janus problem, vividly illustrated in Figure 1(a). This issue primarily stems from the inherent viewpoint biases in 2D diffusion models trained on extensive internetscale datasets, as demonstrated in Figure 1(b). These biases predispose the generated 3D models to overfit, typically manifesting as repetitive frontal views and other geometric distortions.
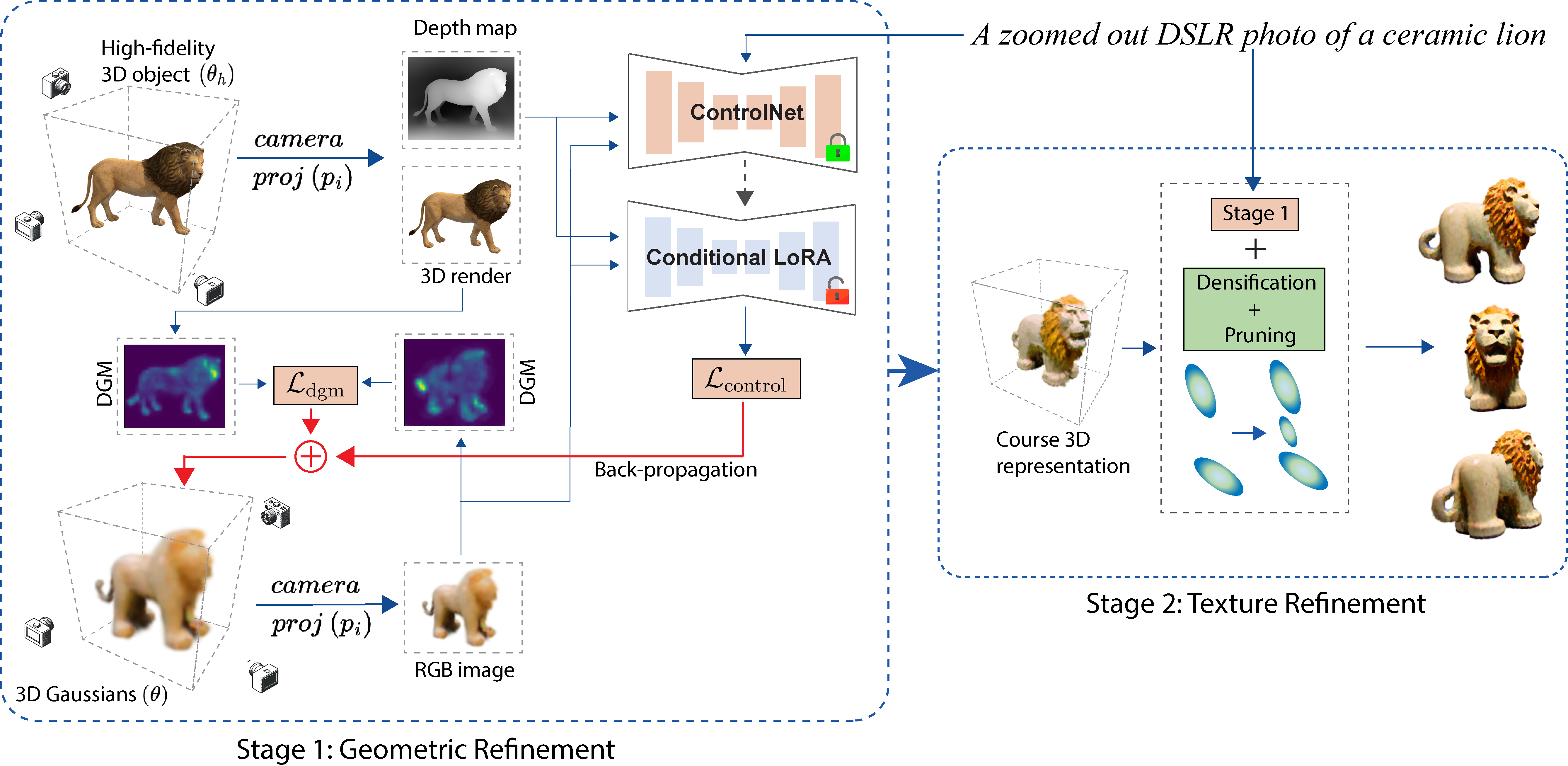
In this paper, we introduce MT3D, a novel moment-based text-to-3D generative model. MT3D is a 2D lifting technique designed to generate high-quality, geometrically consistent objects by learning geometry from a high-fidelity 3D object. Traditional 2D lifting techniques uniformly sample images from a 3D representation and subsequently align them with the high-probability images produced by the frozen diffusion model. Our objective is to reduce inherent viewpoint bias and incorporate 3D geometric understanding into our generation pipeline.
Firstly, we utilize ControlNet to address viewpoint bias in diffusion models. ControlNet produces images based on its control signals. As depicted in Figure 3, images generated by ControlNet, when conditioned on various depth maps, demonstrate its ability to produce images from multiple viewpoints, thereby reducing viewpoint bias. In this paper, for each view sampled from the 3D representation, we render its corresponding view from a high-fidelity 3D reference object. We then extract a depth map from this rendered view, which serves as the control signal for the diffusion model.
ControlNet mitigates viewpoint bias to a certain extent, but it performs poorly on views that are significantly scarce in the training dataset. For example, as shown in Figure 3, ControlNet generates a poor-quality image when conditioned on a depth map of a more challenging bottom view. In this paper, we employ deep geometric moments (DGM) to explicitly infuse the geometric properties of a reference 3D asset into the generated 3D representation, ensuring that even underrepresented views exhibit coherent geometry. Geometric moments define various shape characteristics and can be visualized as projections of the image onto chosen basis functions. The DGM is inspired by traditional moment calculations, with the significant difference that its basis functions are learned end-to-end through deep learning.
@inproceedings{nath2024deep,
title={Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation},
author={Nath, Utkarsh and Goel, Rajeev and Jeon, Eun Som and Kim, Changhoon and Min, Kyle and Yang, Yezhou and Yang, Yingzhen and Turaga, Pavan},
journal={arXiv preprint arXiv:2408.05938},
year={2024}
}